
- Integrated Benchmarking and Design for Reproducible and Accessible Evaluation of Robotic Agents
- Jacopo Tani, Andrea F. Daniele, Gianmarco Bernasconi, Amaury Camus, Aleksandar Petrov, Anthony Courchesne, Bhairav Mehta, Rohit Suri, Tomasz Zaluska, Matthew R. Walter, Emilio Frazzoli, Liam Paull, Andrea Censi
- 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) October 25-29, 2020, Las Vegas, NV, USA (Virtual)
- ArXiv version download: arXiv:2009.04362v1
- Find the code here
Integrated Benchmarking and Design for Reproducible and Accessible Evaluation of Robotic Agents
Why is this important?
As robotics matures and increases in complexity, it is more necessary than ever that robot autonomy research be reproducible.
Compared to other sciences, there are specific challenges to benchmarking autonomy, such as the complexity of the software stacks, the variability of the hardware and the reliance on data-driven techniques, amongst others.
We describe a new concept for reproducible robotics research that integrates development and benchmarking, so that reproducibility is obtained by design from the beginning of the research/development processes.
We first provide the overall conceptual objectives to achieve this goal and then a concrete instance that we have built: the DUCKIENet.
The Duckietown Automated Laboratories (Autolabs)
One of the central components of this setup is the Duckietown Autolab (DTA), a remotely accessible standardized setup that is itself also relatively low-cost and reproducible.
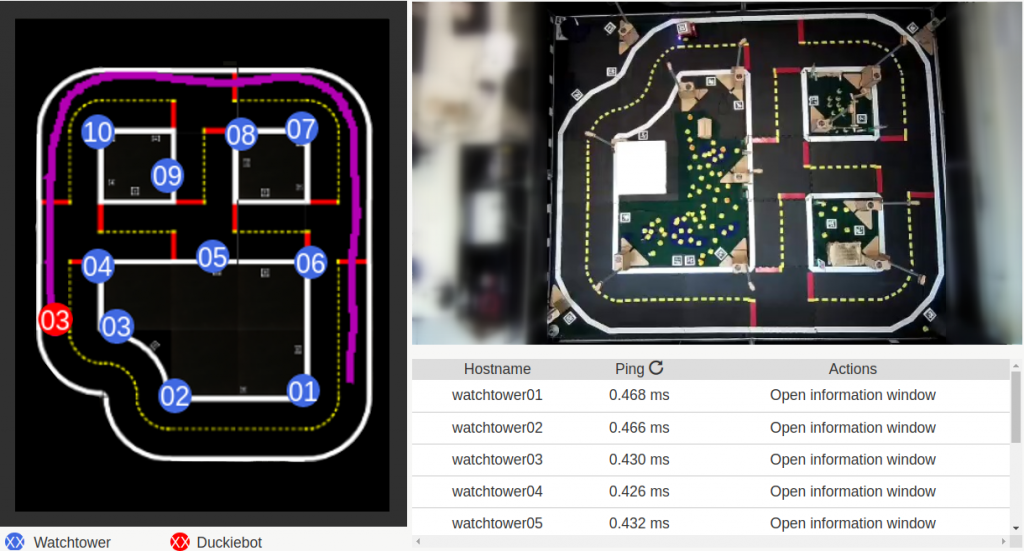
DTAs include an off-the-shelf camera-based localization system. The accessibility of the hardware testing environment through enables experimental benchmarking that can be performed on a network of DTAs in different geographical locations.

The DUCKIENet
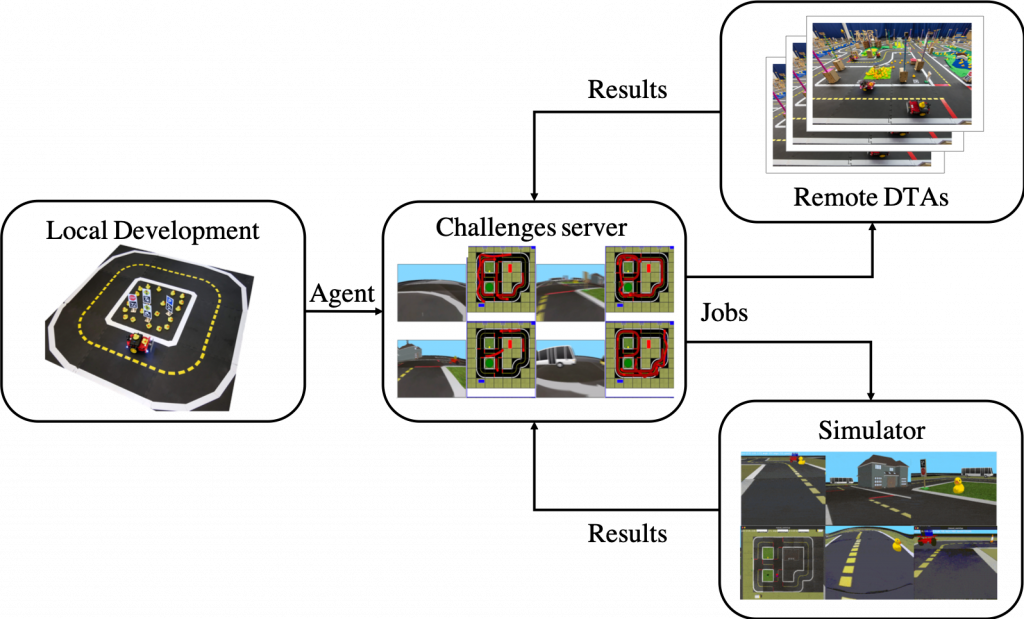
When evaluating agents, careful definition of interfaces allows users to choose among local versus remote evaluation using simulation, logs, or remote automated hardware setups. The Decentralized Urban Collaborative Benchmarking Environment Network (DUCKIENet) is an instantiation of this design based on the Duckietown platform that provides an accessible and reproducible framework focused on autonomous vehicle fleets operating in model urban environments.
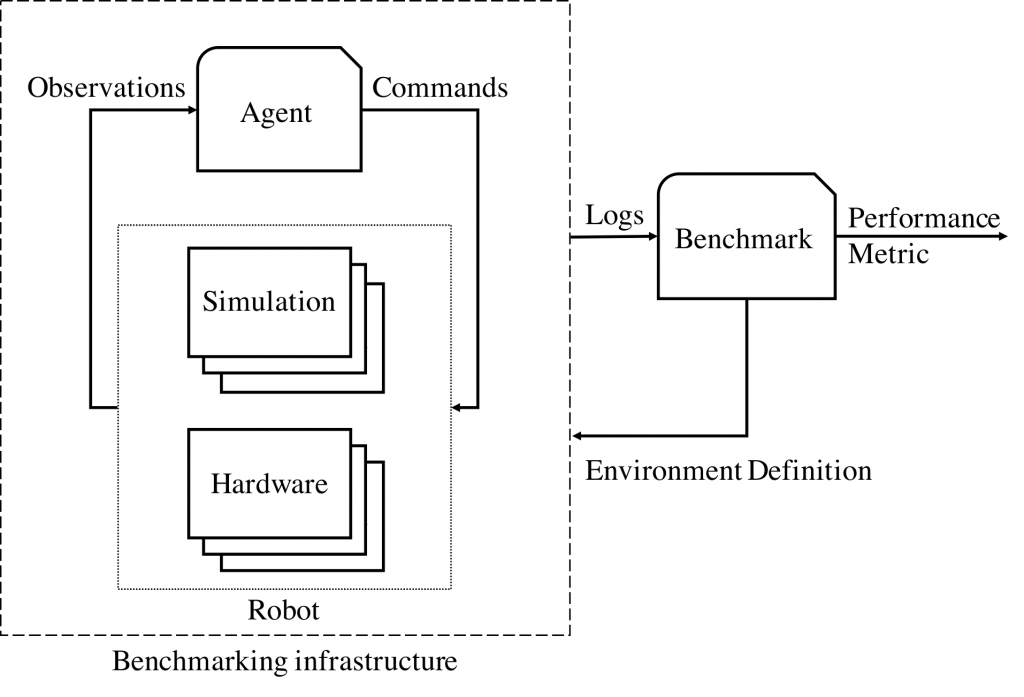
The DUCKIENet enables users to develop and test a wide variety of different algorithms using available resources (simulator, logs, cloud evaluations, etc.), and then deploy their algorithms locally in simulation, locally on a robot, in a cloud-based simulation, or on a real robot in a remote lab. In each case, the submitter receives feedback and scores based on well-defined metrics.
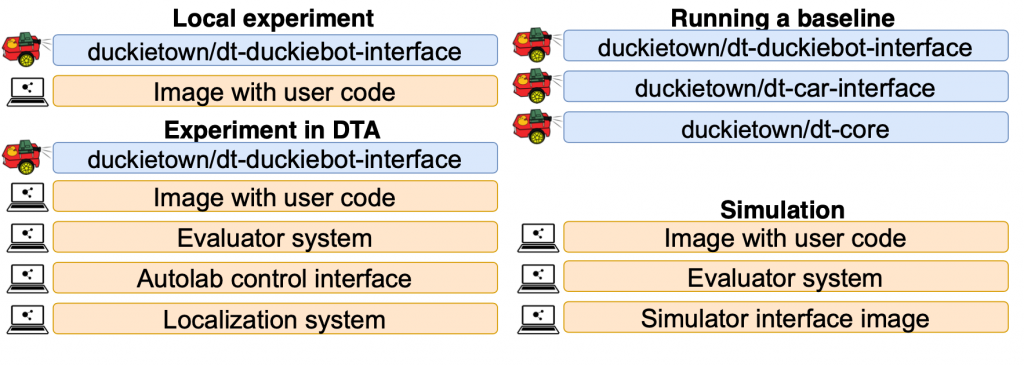
Validation
We validate the system by analyzing the repeatability of experiments conducted using the infrastructure and show that there is low variance across different robot hardware and across different remote labs. We built DTAs at the Swiss Federal Institute of Technology in Zurich (ETHZ) and at the Toyota Technological Institute at Chicago (TTIC).
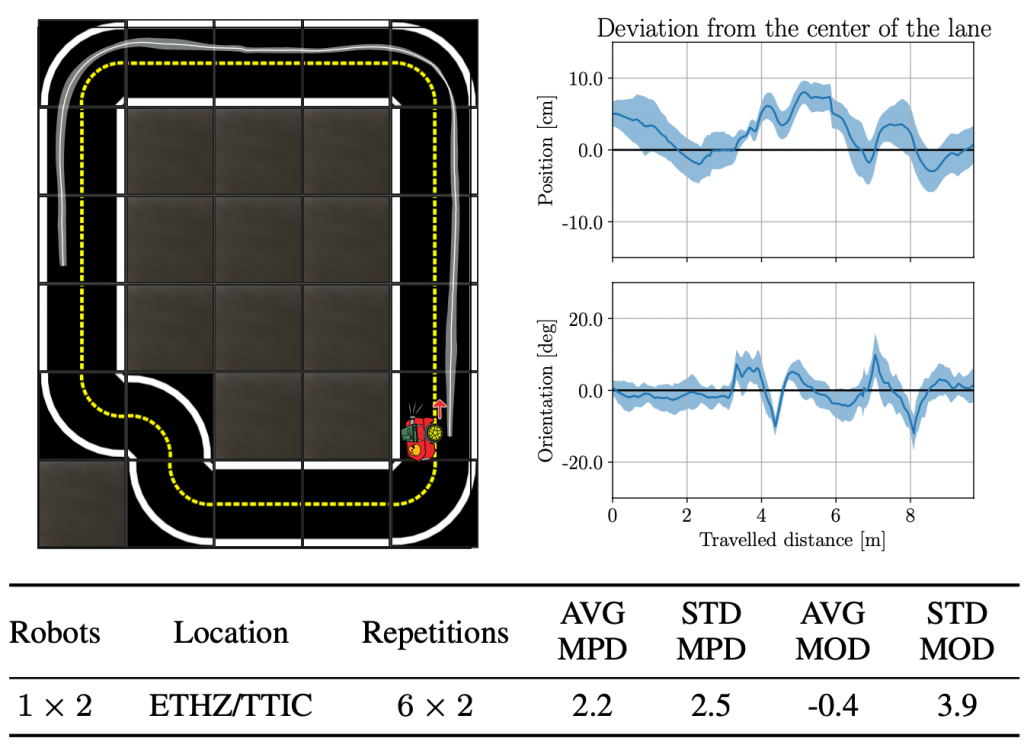
Conclusions
Our contention is that there is a need for stronger efforts towards reproducible research for robotics, and that to achieve this we need to consider the evaluation in equal terms as the algorithms themselves. In this fashion, we can obtain reproducibility by design through the research and development processes. Achieving this on a large-scale will contribute to a more systemic evaluation of robotics research and, in turn, increase the progress of development.


If you found this interesting, you might want to: